Всего учтено крепостных: 0
Источник: Тройницкий А.Г. Александр Григорьевич (1807-1871). Крепостное население в России по 10-й народной переписи. — Спб., 1861.
Поиск сведений
Российские помещики владели крестьянами сотни лет, но давайте для простоты ограничимся данными на момент отмены крепостного права.
Если гуглить сведения о крупнейших помещиках "в лоб", то довольно быстро находятся статьи, в том или ином виде повторяющие одни и те же данные: самый крупный помещик в 1860 г. — это Сергей Дмитриевич Шереметев, следом идут князь Петр Витгенштейн и графиня Наталия Павловна Строганова. Источник этих данных — книга Д. Ливена "Аристократия в Европе. 1815-1914" (М., 2000). Это изначально англоязычная монография, автор анализирует сведения о дворянах разных стран, много внимания уделяет России.
В одной из таблиц он дает вот такие данные:
Поиск сведений
Российские помещики владели крестьянами сотни лет, но давайте для простоты ограничимся данными на момент отмены крепостного права.
Если гуглить сведения о крупнейших помещиках "в лоб", то довольно быстро находятся статьи, в том или ином виде повторяющие одни и те же данные: самый крупный помещик в 1860 г. — это Сергей Дмитриевич Шереметев, следом идут князь Петр Витгенштейн и графиня Наталия Павловна Строганова. Источник этих данных — книга Д. Ливена "Аристократия в Европе. 1815-1914" (М., 2000). Это изначально англоязычная монография, автор анализирует сведения о дворянах разных стран, много внимания уделяет России.
В одной из таблиц он дает вот такие данные:
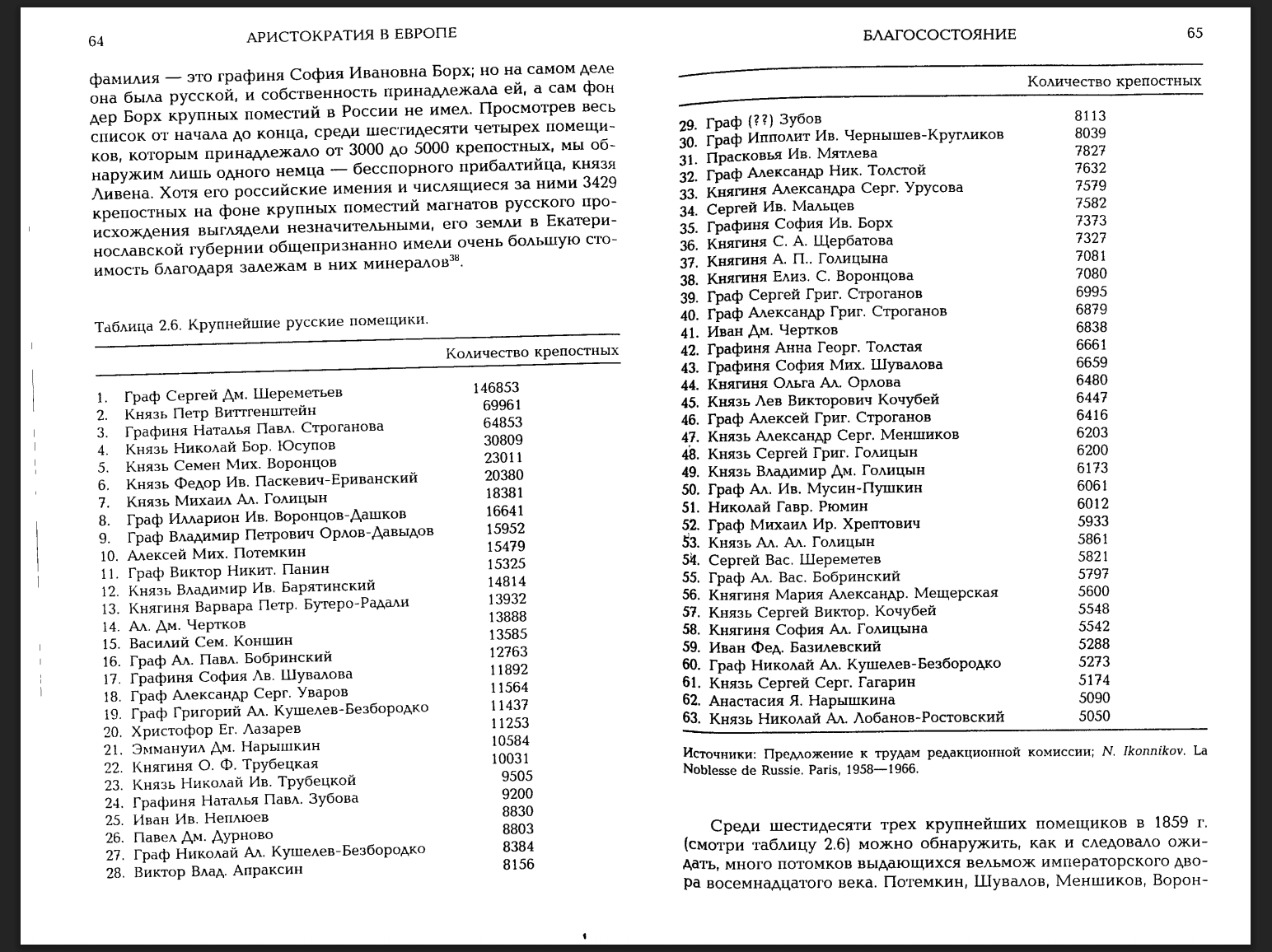
Отлично, начало есть. Ливен при этом ссылается на "Предложение к трудам редакционной комиссии" и на генеалогический справочник Н.Ф. Иконникова. Где Иконников в своем 50-томном труде приводил такие данные, я искать не стал, но вот сверить их по "Приложениям (sic!) к трудам редакционных комиссий" стоит.
Но сначала попробуем дополнительно поискать не поисковиком, а каким-нибудь ИИ-инструментом. Для подобного мне больше нравится Perplexity, но в целом в режиме DeepSearch и подобных с таким поиском может справиться любая популярная модель — ChatGPT, Gemini и проч.
Мой запрос к Perplexity: "Дай топ-50 самых крупных помещиков Российской империи перед отменой крепостного права", он дает вот такой результат. Он находит сведения о той же книги Ливена, приводит данные из нее в виде таблицы, при этом дает дополнительные данные о топе помещиков. Вроде неплохо? Однозначно не скажешь — с одной стороны, данные из книжного источника найдены и приведены сразу в табличном распознанном виде, но с другой — данные о помещиках очень хаотичны и почти во всем неточны (спутаны разные Чертковы, Нарышкины названы князьями и графами, откуда-то берется "граф Петр Араловский Паскевич-Эриванский" и проч.). Пользоваться результатом нельзя, хотя на поверхностный взгляд он выглядит хорошо — данные упорядочены, указаны их источники.
Gemini 3 Pro в "обычном" режиме (не Deep Research) дает на этот же вопрос вот такой ответ:
Отлично, начало есть. Ливен при этом ссылается на "Предложение к трудам редакционной комиссии" и на генеалогический справочник Н.Ф. Иконникова. Где Иконников в своем 50-томном труде приводил такие данные, я искать не стал, но вот сверить их по "Приложениям (sic!) к трудам редакционных комиссий" стоит.
Но сначала попробуем дополнительно поискать не поисковиком, а каким-нибудь ИИ-инструментом. Для подобного мне больше нравится Perplexity, но в целом в режиме DeepSearch и подобных с таким поиском может справиться любая популярная модель — ChatGPT, Gemini и проч.
Мой запрос к Perplexity: "Дай топ-50 самых крупных помещиков Российской империи перед отменой крепостного права", он дает вот такой результат. Он находит сведения о той же книги Ливена, приводит данные из нее в виде таблицы, при этом дает дополнительные данные о топе помещиков. Вроде неплохо? Однозначно не скажешь — с одной стороны, данные из книжного источника найдены и приведены сразу в табличном распознанном виде, но с другой — данные о помещиках очень хаотичны и почти во всем неточны (спутаны разные Чертковы, Нарышкины названы князьями и графами, откуда-то берется "граф Петр Араловский Паскевич-Эриванский" и проч.). Пользоваться результатом нельзя, хотя на поверхностный взгляд он выглядит хорошо — данные упорядочены, указаны их источники.
Gemini 3 Pro в "обычном" режиме (не Deep Research) дает на этот же вопрос вот такой ответ:
То есть примерно то же самое. Где-то лучше, где-то хуже, но суть одна — использовать такие данные в серьезной работе нельзя.
То есть примерно то же самое. Где-то лучше, где-то хуже, но суть одна — использовать такие данные в серьезной работе нельзя.
Результат с Deep Research куда интереснее. Он искал данные минут 20, в процессе рассуждения бросался такими фразами: "Я приступаю к анализу структуры землевладения накануне отмены крепостного права, сосредоточившись на данных 10-й народной переписи 1858 года и материалах Редакционных комиссий 1860 года", "Для разрешения проблемы отсутствия готового консолидированного перечня я перехожу к глубокой проработке приложений к трудам Редакционных комиссий и академических работ историков-аграрников, таких как П. А. Зайончковский и Б. Г. Литвак.

Процесс рассуждения Gemini 3 Pro в режиме Deep Research
Результат с Deep Research куда интереснее. Он искал данные минут 20, в процессе рассуждения бросался такими фразами: "Я приступаю к анализу структуры землевладения накануне отмены крепостного права, сосредоточившись на данных 10-й народной переписи 1858 года и материалах Редакционных комиссий 1860 года", "Для разрешения проблемы отсутствия готового консолидированного перечня я перехожу к глубокой проработке приложений к трудам Редакционных комиссий и академических работ историков-аграрников, таких как П. А. Зайончковский и Б. Г. Литвак.
Процесс рассуждения Gemini 3 Pro в режиме Deep Research

А не так, например, то, что Сергею Дмитриевичу Шереметеву к 1860 г. было всего 16 лет, и в "Приложениях к трудам..." он не упоминается ни разу.
А не так, например, то, что Сергею Дмитриевичу Шереметеву к 1860 г. было всего 16 лет, и в "Приложениях к трудам..." он не упоминается ни разу.
Вот это поворот. Несмотря на якобы обращения к первоисточникам и к самому Зайончковскому бОльшая часть информации взята из статей, первооснову которых составила та же таблица из книги Ливена. А Ливен банально перепутал Сергея Дмитриевича и его отца — графа Дмитрия Николаевича Шереметева. Как перепутал еще много чего. Его данные, якобы основанные на "Приложениях...", попали в статьи, по оригиналам авторы статей не сверялись, в итоге всё попало в результаты от ИИ (все, как в обычных исследованиях, впрочем!).
Вывод по первому пункту такой: Современные ИИ-модели неплохо справляются с поиском в интернете, могут для одного запроса приводить ссылки, выстраивать выглядящий достоверно текст. Но полностью полагаться на его точность нельзя, как бы правдиво не выглядели рассуждения.
Лучший (хотя и неверный по сути) результат здесь показывает режим Deep Research oт Google Gemini 3 Pro, результаты от Perplexity и "обычного" Gemini — полнейшая ерунда.
Вот это поворот. Несмотря на якобы обращения к первоисточникам и к самому Зайончковскому бОльшая часть информации взята из статей, первооснову которых составила та же таблица из книги Ливена. А Ливен банально перепутал Сергея Дмитриевича и его отца — графа Дмитрия Николаевича Шереметева. Как перепутал еще много чего. Его данные, якобы основанные на "Приложениях...", попали в статьи, по оригиналам авторы статей не сверялись, в итоге всё попало в результаты от ИИ (все, как в обычных исследованиях, впрочем!).
Вывод по первому пункту такой: Современные ИИ-модели неплохо справляются с поиском в интернете, могут для одного запроса приводить ссылки, выстраивать выглядящий достоверно текст. Но полностью полагаться на его точность нельзя, как бы правдиво не выглядели рассуждения.
Лучший (хотя и неверный по сути) результат здесь показывает режим Deep Research oт Google Gemini 3 Pro, результаты от Perplexity и "обычного" Gemini — полнейшая ерунда.
Распознавание текстов книг
Едем дальше. Ну хорошо, Ливен ошибся, следом ошиблись все остальные, но табличку-то он интересную приводит. Можно ли ее распознать и перевести в табличку для Excel'я? Ну и вообще — можно ли весь текст книги распознать с помощью ИИ? "— Эй, Алиса, распознай-ка текст книги и дай мне его в виде вордовского файла?" — такое возможно?
И да, и нет.
Cкармливаем нескольким моделям (Chat GPT и Gemini) страницу с таблицей выше. Результат одинаково неплох — распознавание идет без существенных ошибок, четко разделяется обычный текст и таблицы. Но распознать так pdf-ку на 200-300 страниц, не удастся — такая pdf-ка сразу съест все токены и продвинуться не получится.
Вполне возможно распознавать частями — по 10-15 страниц, но даже это может оказаться перебором: любые модели могут зависнуть на середине процесса, поэтому лучше их особо не торопить. Серьезные полноценные модели, которые могли бы сразу распознавать тексты любого объема, мне не встречались, хотя вот буквально на днях вышла некая OCR-3 от Mistral, которая в видосиках показывает какие-то чудеса распознавания, но полноценно потестировать ее мне не удалось.
В этой части процесса пора перейти от вроде как ошибочного Ливена к оригинальным "Приложениям к трудам..." (шеститомник, изданный в 1860 г.), и к другому источнику по статистике крепостных — книге А.Н. Тройницкого "Крепостное население в России по 10-й народной переписи" (1861 г.). "Приложения" почти полностью состоят из таблиц имений с указаниями владельцев и числом душ в них, книга Тройницкого — из подробного описания положения крепостных накануне отмены крепостного права и тоже из таблиц. Поехали распознавать!
Распознавание текстов книг
Едем дальше. Ну хорошо, Ливен ошибся, следом ошиблись все остальные, но табличку-то он интересную приводит. Можно ли ее распознать и перевести в табличку для Excel'я? Ну и вообще — можно ли весь текст книги распознать с помощью ИИ? "— Эй, Алиса, распознай-ка текст книги и дай мне его в виде вордовского файла?" — такое возможно?
И да, и нет.
Cкармливаем нескольким моделям (Chat GPT и Gemini) страницу с таблицей выше. Результат одинаково неплох — распознавание идет без существенных ошибок, четко разделяется обычный текст и таблицы. Но распознать так pdf-ку на 200-300 страниц, не удастся — такая pdf-ка сразу съест все токены и продвинуться не получится.
Вполне возможно распознавать частями — по 10-15 страниц, но даже это может оказаться перебором: любые модели могут зависнуть на середине процесса, поэтому лучше их особо не торопить. Серьезные полноценные модели, которые могли бы сразу распознавать тексты любого объема, мне не встречались, хотя вот буквально на днях вышла некая OCR-3 от Mistral, которая в видосиках показывает какие-то чудеса распознавания, но полноценно потестировать ее мне не удалось.
В этой части процесса пора перейти от вроде как ошибочного Ливена к оригинальным "Приложениям к трудам..." (шеститомник, изданный в 1860 г.), и к другому источнику по статистике крепостных — книге А.Н. Тройницкого "Крепостное население в России по 10-й народной переписи" (1861 г.). "Приложения" почти полностью состоят из таблиц имений с указаниями владельцев и числом душ в них, книга Тройницкого — из подробного описания положения крепостных накануне отмены крепостного права и тоже из таблиц. Поехали распознавать!
Вывод простой: на идеальных текстах — с идеальным качеством скана, с "идеальным" шрифтом, с более-менее понятной структурой — современные ИИ-модели показывают высокое качество распознавания. Но если что-то из этого неидеально — качество падает существенно.
И это я не говорю про распознавание рукописных текстов (одно из самых частых требований к тому, чего хотелось бы от ИИ). Распознавать рукописные тексты — даже в современной орфографии — обычные ИИ-модели не умеют вовсе. То, что уже привычно, от "Яндекса", т.е. распознанные документы, по которым можно вести поиск — это результат, достигнутый в т.ч. с помощью искусственного интеллекта, но гораздо более сложным путем, чем пока доступен в обычных моделях. Там это результат большого количества ручного обучения, "натаскивания" алгоритмов на отдельные элементы документа, сочетания букв и проч.
Вывод простой: на идеальных текстах — с идеальным качеством скана, с "идеальным" шрифтом, с более-менее понятной структурой — современные ИИ-модели показывают высокое качество распознавания. Но если что-то из этого неидеально — качество падает существенно.
И это я не говорю про распознавание рукописных текстов (одно из самых частых требований к тому, чего хотелось бы от ИИ). Распознавать рукописные тексты — даже в современной орфографии — обычные ИИ-модели не умеют вовсе. То, что уже привычно, от "Яндекса", т.е. распознанные документы, по которым можно вести поиск — это результат, достигнутый в т.ч. с помощью искусственного интеллекта, но гораздо более сложным путем, чем пока доступен в обычных моделях. Там это результат большого количества ручного обучения, "натаскивания" алгоритмов на отдельные элементы документа, сочетания букв и проч.
Структурирование данных
Наконец, то, в чем ИИ начинает проявляться в полной мере.
Напомню задачу: нужно собрать, структурировать и визуализировать данные о крупнейших помещиках перед реформой 1861 г. Данные Ливена мы отмели (там ошибки, да и их мало), остались "Приложения..." и общестатистические таблицы Тройницкого.
Медленно и несовременно мне все же удалось перевести общие данные Тройницкого по крепостным в каждом уезде в таблицы на Google Docs — пришлось, распознав их через Gemini, вручную сверять каждое число, исправляя ошибочные "5"-ки и "3"-ки. Попутно при этом обнаружилась масса особенностей. Тройницкий явно обобщал данные не с помощью ИИ, поэтому у него есть ошибки — например, указанные промежуточные суммы не всегда совпадают с реальными суммами слагаемых, в таблицах по уездам пропущен существовавший в 1860 г. Сургутский уезд Тобольской губернии, но приведен не существовавший к тому времени Колыванский уезд Томской губернии.
Что же до перевода в электронный вид таблиц из "Приложений...", то добиться сколько-нибудь внятного результата путем ИИ-распознавания не удалось. В процессе добивания обнаружилось, что сведения из этого источника уже переведены в электронный вид — на сайте Familio в разделе "Справочников". Гигантский труд был сделан, по-видимому, вручную и повторяет как многочисленные ошибки оригинала, так и добавляет новые. Так или иначе данные оттуда удалось перенести в тот же Google Docs (ИИ тут тоже помог — правильно сформулированный запрос после пары десятков итераций дал нужный результат).
Дальше самая интересная и долгая часть процесса. В "Приложениях" сведения об именах помещиков приведены как Бог на душу положит: "Гр. Дм. Ник. Шереметев", "Граф Дмитрий Николаевич Шереметев", "Гр. Дмитрий Ник. Шереметьев", "Димитрий Ник. Шерем-ьев" — по десятку, а то и больше вариантов одного имени. Как все это унифицировать? Данные уже в таблице, теоретически можно искать каждый вариант поиском по таблице и исправлять его на какой-то унифицированный. Но учтенных помещиков тысячи! Каждого так не унифицируешь, да и сходу в голову не придет искать вместо, например, Олсуфьева какого-нибудь Алсуфева.
Структурирование данных
Наконец, то, в чем ИИ начинает проявляться в полной мере.
Напомню задачу: нужно собрать, структурировать и визуализировать данные о крупнейших помещиках перед реформой 1861 г. Данные Ливена мы отмели (там ошибки, да и их мало), остались "Приложения..." и общестатистические таблицы Тройницкого.
Медленно и несовременно мне все же удалось перевести общие данные Тройницкого по крепостным в каждом уезде в таблицы на Google Docs — пришлось, распознав их через Gemini, вручную сверять каждое число, исправляя ошибочные "5"-ки и "3"-ки. Попутно при этом обнаружилась масса особенностей. Тройницкий явно обобщал данные не с помощью ИИ, поэтому у него есть ошибки — например, указанные промежуточные суммы не всегда совпадают с реальными суммами слагаемых, в таблицах по уездам пропущен существовавший в 1860 г. Сургутский уезд Тобольской губернии, но приведен не существовавший к тому времени Колыванский уезд Томской губернии.
Что же до перевода в электронный вид таблиц из "Приложений...", то добиться сколько-нибудь внятного результата путем ИИ-распознавания не удалось. В процессе добивания обнаружилось, что сведения из этого источника уже переведены в электронный вид — на сайте Familio в разделе "Справочников". Гигантский труд был сделан, по-видимому, вручную и повторяет как многочисленные ошибки оригинала, так и добавляет новые. Так или иначе данные оттуда удалось перенести в тот же Google Docs (ИИ тут тоже помог — правильно сформулированный запрос после пары десятков итераций дал нужный результат).
Дальше самая интересная и долгая часть процесса. В "Приложениях" сведения об именах помещиков приведены как Бог на душу положит: "Гр. Дм. Ник. Шереметев", "Граф Дмитрий Николаевич Шереметев", "Гр. Дмитрий Ник. Шереметьев", "Димитрий Ник. Шерем-ьев" — по десятку, а то и больше вариантов одного имени. Как все это унифицировать? Данные уже в таблице, теоретически можно искать каждый вариант поиском по таблице и исправлять его на какой-то унифицированный. Но учтенных помещиков тысячи! Каждого так не унифицируешь, да и сходу в голову не придет искать вместо, например, Олсуфьева какого-нибудь Алсуфева.

Потенциальные совпадения, которые предлагал унифицировать Gemini
Потенциальные совпадения, которые предлагал унифицировать Gemini
Но это только списки потенциальных правок. Напрямую заставить в чате менять данные в готовой таблице нельзя — вот тебе список, заменяй все сам, дорогой кожаный мешок. И тут на помощь приходит схема, в которой роль ИИ-моделей на мой взгляд существенно недооценена.
Если нельзя что-то сделать прямо, можно сделать в обход — просто попросив создать инструмент для реализации той или иной задачи.
Если нельзя заставить модель разом найти все потенциальные совпадения и унифицировать их, то можно попросить написать скрипт, сервис, приложение, которое это сделают уже не с помощью ИИ, а с помощью проверенных библиотек.
Но это только списки потенциальных правок. Напрямую заставить в чате менять данные в готовой таблице нельзя — вот тебе список, заменяй все сам, дорогой кожаный мешок. И тут на помощь приходит схема, в которой роль ИИ-моделей на мой взгляд существенно недооценена.
Если нельзя что-то сделать прямо, можно сделать в обход — просто попросив создать инструмент для реализации той или иной задачи.
Если нельзя заставить модель разом найти все потенциальные совпадения и унифицировать их, то можно попросить написать скрипт, сервис, приложение, которое это сделают уже не с помощью ИИ, а с помощью проверенных библиотек.
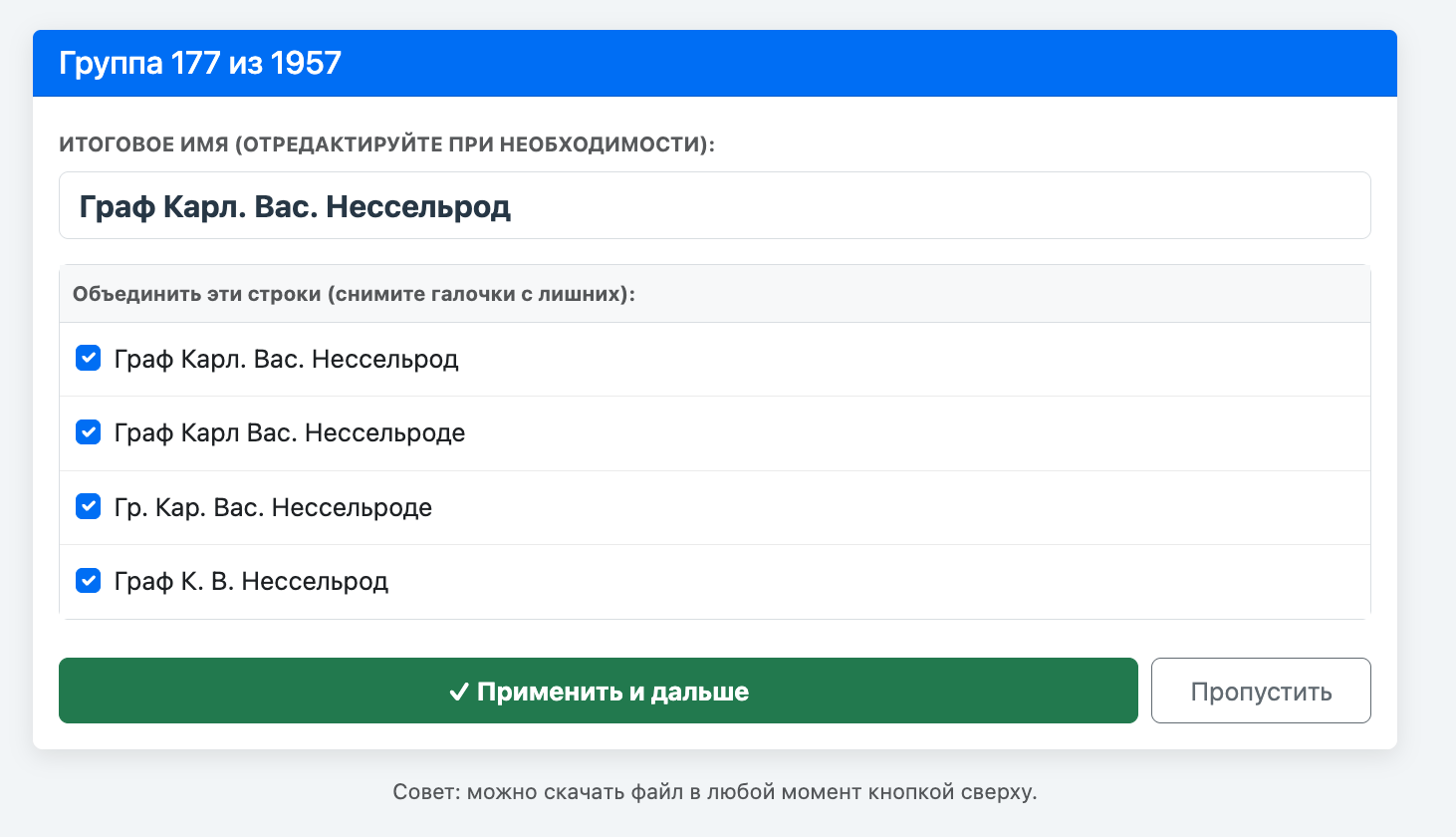
Как все работало в созданной программе.
Как все работало в созданной программе.
Дальше пришлось объединять или пропускать потенциальные совпадения (тысячи их! но несравнимо быстрее, чем через найти-заменить в Excel), время от времени варьируя степень "возможной похожести". Результат оказался достаточно удобоваримым. Вряд ли удалось объединить всех и вся (например, М. Голицын и Михаил Николаевич Голицын — это один и тот же человек, или нет; такие неочевидные варианты пропускались), но осмысленности и структурности в таблице стало на порядки больше.
Вывод проще прежнего: в структуризации и анализе данных ИИ незаменим — если чего-то нельзя сделать непосредственно в чате (например, перевести текст в таблицу там можно, а заставить заменять сотни строк — нельзя), то можно создать для этого дополнительный инструмент, функционал и сложность которого зависит, наверное, только от фантазии.
Дальше пришлось объединять или пропускать потенциальные совпадения (тысячи их! но несравнимо быстрее, чем через найти-заменить в Excel), время от времени варьируя степень "возможной похожести". Результат оказался достаточно удобоваримым. Вряд ли удалось объединить всех и вся (например, М. Голицын и Михаил Николаевич Голицын — это один и тот же человек, или нет; такие неочевидные варианты пропускались), но осмысленности и структурности в таблице стало на порядки больше.
Вывод проще прежнего: в структуризации и анализе данных ИИ незаменим — если чего-то нельзя сделать непосредственно в чате (например, перевести текст в таблицу там можно, а заставить заменять сотни строк — нельзя), то можно создать для этого дополнительный инструмент, функционал и сложность которого зависит, наверное, только от фантазии.
Визуализация данных
Почти всё! В этой части будут мои любимые карты и много табличек.
Данные нашли, худо-бедно распознали, не-худо-не-бедно и с большим количеством ручной работы перевели в "сырые" таблицы. Что с ними делать дальше? Ну, например, перевести некрасивые таблички в красивые. Это проще всего: "хочу такую-то таблицу, но чтобы было 3 колонки, номера строк в кружочках, первые три места в цвет золота-серебра-бронзы", и, пожалуйста, что-то такое. Это все тот же Ливен, только не в виде строчек из книги.
Визуализация данных
Почти всё! В этой части будут мои любимые карты и много табличек.
Данные нашли, худо-бедно распознали, не-худо-не-бедно и с большим количеством ручной работы перевели в "сырые" таблицы. Что с ними делать дальше? Ну, например, перевести некрасивые таблички в красивые. Это проще всего: "хочу такую-то таблицу, но чтобы было 3 колонки, номера строк в кружочках, первые три места в цвет золота-серебра-бронзы", и, пожалуйста, что-то такое. Это все тот же Ливен, только не в виде строчек из книги.
Что еще? Конечно, показать на карте!
Карты я эксплуатирую примерно одни и те же — созданные 25 лет назад контуры губерний и уездов Российской империи по состоянию на 1897 год. В них множество мелких недочетов, которые я постепенно исправляю — от неправильных названий уездов (например, "Мещонский" в Калужской губернии, "Курмыжский" в Калужской и т.п.) до отображения никогда не существоваших уездов (например, Еланский уезд в Саратовской губернии я отловил только сейчас).
Представлять на карте 1897 года данные из 1860-го, конечно, не совсем верно. Некоторые уезды-1897 еще не существовали в 1860 г., и наоборот. По-хорошему надо заново их отрисовать для каждого исторического периода.
Виды картографически визуализаций могут быть в общем какие угодно, но здесь хорошего готового решения ИИ может вовсе не предложить — любая такая визуализация это череда проб и ошибок, доделок и переделок. Другое дело, что однажды достигнув устраивающего результата, можно в следующих вариантах давать его ИИ в виде референса — "хочу, чтобы кнопки были такими же, но с перламутровым отливом". При наличии референсов модели справляются с визуализациями гораздо лучше, хотя и здесь проявляется основная их боль и печаль — галлюцинации; когда в визуализацию добавляется то, чего не просили, убирается то, что десять раз прошено не убирать и т.п.
В общем, долго ли коротко таблицы Тройницкого с нечитаемыми пятерками и единичками превращаются вот в это — тепловую карту с поуездными данными по числу крепостных (некоторые уезды не существовали в 1897 г. и их на карте нет — это серьезное поле для доработки; например, отсутствует Миусский округ — один из лидеров по числу крепостных).
Что еще? Конечно, показать на карте!
Карты я эксплуатирую примерно одни и те же — созданные 25 лет назад контуры губерний и уездов Российской империи по состоянию на 1897 год. В них множество мелких недочетов, которые я постепенно исправляю — от неправильных названий уездов (например, "Мещонский" в Калужской губернии, "Курмыжский" в Калужской и т.п.) до отображения никогда не существоваших уездов (например, Еланский уезд в Саратовской губернии я отловил только сейчас).
Представлять на карте 1897 года данные из 1860-го, конечно, не совсем верно. Некоторые уезды-1897 еще не существовали в 1860 г., и наоборот. По-хорошему надо заново их отрисовать для каждого исторического периода.
Виды картографически визуализаций могут быть в общем какие угодно, но здесь хорошего готового решения ИИ может вовсе не предложить — любая такая визуализация это череда проб и ошибок, доделок и переделок. Другое дело, что однажды достигнув устраивающего результата, можно в следующих вариантах давать его ИИ в виде референса — "хочу, чтобы кнопки были такими же, но с перламутровым отливом". При наличии референсов модели справляются с визуализациями гораздо лучше, хотя и здесь проявляется основная их боль и печаль — галлюцинации; когда в визуализацию добавляется то, чего не просили, убирается то, что десять раз прошено не убирать и т.п.
В общем, долго ли коротко таблицы Тройницкого с нечитаемыми пятерками и единичками превращаются вот в это — тепловую карту с поуездными данными по числу крепостных (некоторые уезды не существовали в 1897 г. и их на карте нет — это серьезное поле для доработки; например, отсутствует Миусский округ — один из лидеров по числу крепостных).
А сведения из сборников о работе редакционных комиссий — вот в это. Все (ну, большинство) имена унифицированы, все крупные имения (ну, тоже явно не все) учтены, и тут наконец становится возможным сравнить данные с тех, с которых мы начали — с вроде как ошибочной таблицы Ливена.
И станет видно, что по крайней мере в верхней своей части она не так уж и плоха. Шереметев хотя и не тот, что нужно, но количество крестьян посчитано почти идентично, следующая тройка помещиков верна. Но у автора ИИ же не было!
Итоги, кстати, получаются довольно любопытные. В крупнейшем имении на момент отмены крепостного права — 38 тысяч крестьян мужского пола, "бронзовая" графиня Строганова всеми крестьянами владела в рамках нескольких уездов одной Пермской губернии, "серебряный" Витгенштейн взял серебро засчет десятков скученных имений в западных губерний (ну и за счет тому, что ему, как у большинства соседей в счет шли не только мужчины-крепостные, но и женщины). Есть что пощелкать и подвигать.
А сведения из сборников о работе редакционных комиссий — вот в это. Все (ну, большинство) имена унифицированы, все крупные имения (ну, тоже явно не все) учтены, и тут наконец становится возможным сравнить данные с тех, с которых мы начали — с вроде как ошибочной таблицы Ливена.
И станет видно, что по крайней мере в верхней своей части она не так уж и плоха. Шереметев хотя и не тот, что нужно, но количество крестьян посчитано почти идентично, следующая тройка помещиков верна. Но у автора ИИ же не было!
Итоги, кстати, получаются довольно любопытные. В крупнейшем имении на момент отмены крепостного права — 38 тысяч крестьян мужского пола, "бронзовая" графиня Строганова всеми крестьянами владела в рамках нескольких уездов одной Пермской губернии, "серебряный" Витгенштейн взял серебро засчет десятков скученных имений в западных губерний (ну и за счет тому, что ему, как у большинства соседей в счет шли не только мужчины-крепостные, но и женщины). Есть что пощелкать и подвигать.
Бонусом — вот такая штука, тоже сделанная не без ИИ. Это отабличенная версия описей фонда 577 РГИА (Главное выкупное учреждение), в которой удобно и просто искать сведения о помещиках, владевших крестьянами на излете крепостного права. Здесь уже не только крупные имения, есть возможность быстро найти "свои" деревни и "своих" помещиков.
Бонусом — вот такая штука, тоже сделанная не без ИИ. Это отабличенная версия описей фонда 577 РГИА (Главное выкупное учреждение), в которой удобно и просто искать сведения о помещиках, владевших крестьянами на излете крепостного права. Здесь уже не только крупные имения, есть возможность быстро найти "свои" деревни и "своих" помещиков.
Еще один бонус — ИИ-инфографика от NotebookLM (это тоже Google). Этот ИИ-извод позволяет рисовать инфографику, делать презентации (в т.ч. аудио и видео) на основе загруженных файлов. Тут на входе — excel-табличка на основе данных Тройницкого, а на выходе вот такая картинка.
Небольшой лайфхак: лучше инфографика делается, если задать в настройках не русский, а английский язык. А потом попросить Nano Banana 2 полученную картинку перевести на русский. Без такого лайфхака надписи на русском выглядят как абракадабра.
Еще один бонус — ИИ-инфографика от NotebookLM (это тоже Google). Этот ИИ-извод позволяет рисовать инфографику, делать презентации (в т.ч. аудио и видео) на основе загруженных файлов. Тут на входе — excel-табличка на основе данных Тройницкого, а на выходе вот такая картинка.
Небольшой лайфхак: лучше инфографика делается, если задать в настройках не русский, а английский язык. А потом попросить Nano Banana 2 полученную картинку перевести на русский. Без такого лайфхака надписи на русском выглядят как абракадабра.

Выводы
А выводы всему этому написал Gemini (узнаете его по любви к маркированным спискам и к конструкции "Это не..., а...").
Подводя итог эксперименту по поиску и обработке данных о помещичьих имениях 1860 года, можно выделить несколько ключевых аспектов использования ИИ в исторических и генеалогических исследованиях:
Общий итог: ИИ сегодня — это не замена исследователю, а эффективный «соавтор-подмастерье». Он радикально ускоряет рутинные процессы (сортировку, кодинг, первичный поиск), но финальная ответственность за историческую достоверность по-прежнему лежит на человеке. Мы находимся в точке, где ИИ уже может построить сложнейший инструмент для анализа прошлого, но всё еще не может гарантировать точность каждой цифры в нем.
Выводы
А выводы всему этому написал Gemini (узнаете его по любви к маркированным спискам и к конструкции "Это не..., а...").
Подводя итог эксперименту по поиску и обработке данных о помещичьих имениях 1860 года, можно выделить несколько ключевых аспектов использования ИИ в исторических и генеалогических исследованиях:
Общий итог: ИИ сегодня — это не замена исследователю, а эффективный «соавтор-подмастерье». Он радикально ускоряет рутинные процессы (сортировку, кодинг, первичный поиск), но финальная ответственность за историческую достоверность по-прежнему лежит на человеке. Мы находимся в точке, где ИИ уже может построить сложнейший инструмент для анализа прошлого, но всё еще не может гарантировать точность каждой цифры в нем.